Ein Gedanke zu Vibe-Coding
Ich lese viele Artikel über dieses Vibe-Coding. Wobei der Begriff nicht mal genau definiert ist, aber ungefähr besagt: Programmieren mit integrierter Unterstützung durch ein LLM. Oder in anderen Worten: das durch künstliche Intelligenz unterstützte Programmieren. Ich selbst verwende es extensiv für viele unwichtige Angelegenheiten.
Ich möchte eine kleine Webanwendung machen für meine Präsentation: Easy. Mit Vibe-Coding geht das in 10 Minuten. Ich möchte meine Daten mit einem Skript auswerten. Die KI schreibt mir dieses Skript schnell. Und so weiter.
Gleichzeitig wird überall gewarnt vor den Gefahren der KI. Gerade die Open-Source-Community hat Probleme damit. Das Engagement an Open-Source-Projekten nimmt nämlich ab. Menschen möchten die Probleme von diesen Projekten gar nicht mehr fixen, sondern finden einen Workaround mittels KI. Die KI konnte die Library lokal ändern oder fand sonst einen Fix. Da der Programmierer selbst nur wenig Code am Ende noch liest, ist er sich gar nicht bewusst, dass ein Problem in einer Library existierte, und fährt fort, als wäre nichts gewesen. Diese Entwicklung (und viele andere) werden kritisiert. Ich möchte in diesem Artikel Parallelen zu vergangenen Entwicklungen aufzeigen und eine Prognose wagen, wohin sich die Programmierwelt entwickeln wird und wie wir uns darauf vorbereiten können.
Computer
Vor 200 Jahren gab es den Beruf des «Computers». Es waren Menschen (meist Frauen), die im Kopf und mit Stift und Papier rechneten. Gab es ein mathematisches Modell für die Berechnung, konnte man diese Frauen anstellen und sie berechneten es. Menschen sind fehlerhaft und somit waren auch immer wieder Resultate falsch. Gleichwohl war es über eine lange Zeit eine wertvolle Aufgabe. Bis der moderne Computer kam. Eine Maschine, die genau das kann. Der Beruf wurde wegrationalisiert.
Stellen wir uns diese Zeit vor. Ein gebrauchter Beruf wurde überflüssig. Aber nicht nur das, auch die Open-Source-Community wurde getroffen. Es gab Bücher mit Logarithmus-Tabellen. Viele nützliche Dinge wurden überflüssig. All dieser Nutzen fiel weg.
Heute
Aus meiner Sicht verhält es sich heute genauso. Viele wichtige Berufe werden überflüssig. (Meiner wahrscheinlich auch.) Doch was passiert, wenn auf einmal Aufgaben, die früher Wochen oder gar Monate dauerten, jetzt in Stunden gemacht werden können? Die ganze alte Infrastruktur für den Informationsaustausch wird überflüssig. Die Open-Source-Projekte werden sich ändern. Es geht nicht mehr um so kleine Sachen wie einen Bugfix, sondern um Features. Neue Fähigkeiten werden bereitgestellt.
Früher war eine Berechnung nur gültig mit korrektem Rechnungsweg. Mit dem Computer interessieren die Zwischenresultate niemanden mehr. Wenn der Algorithmus definiert ist, dann «glaubt» man einfach dem Computer, dass er das schon korrekt macht. Natürlich sind alle Hilfsmittel (Compiler usw.) ebenfalls wichtig. Doch sind viele davon auch nicht öffentlich, folglich muss einfach vertraut werden, dass sie funktionieren. Mit nicht quelloffenen Programmen wird die Kette gebrochen und wir können nicht nachvollziehen, ob ein Ergebnis korrekt ist. Das hat aber kaum jemanden interessiert in der Vergangenheit.
Mit KI verhält es sich gleich. Wir sind nicht mehr an einzelnen Commits interessiert, sondern an Blöcken. Commits werden nur vollständigkeitshalber gespeichert. Doch es wird eine KI-Zusammenfassung der Änderung geben und diese wird das wahre «Diff» sein. Wenn der Code nicht diesem «Diff» entspricht, dann ist das halt ein BUG. Ich glaube, die Menschheit benötigt kein Log für jede Millisekunde. Ich glaube, dass die Abstände zwischen den Logs (genauer gesagt die Grösse der Commits) abhängig von der echten Zeit sind. Ein Log/Commit pro 30min, aber vielleicht auch nur ein Log/Commit pro Halbtag. Was in dieser Zeit erledigt werden kann, wurde mit KI gesteigert, und dadurch werden die «Diffs» riesig. Ähnlich wie bei den Computern: Wir speichern nicht alle Rechenschritte. Wenn es neu berechnet werden kann innerhalb von 30 min, warum soll ich es speichern?
Wir benötigen so ein «Meta-Git». Am Anfang wird das eine LLM-Zusammenfassung von vielen Git-Commits sein. Doch dieses Meta-Git wird sich entwickeln und ein Standard wird kreiert werden. Dieses Mega-Git sollte langfristig weiterentwickelt werden. Wenn ein solcher einzelner «Meta-Commit» ganze Features beinhaltet (was früher ein Pull-Request war, ist heute ein Commit), dann wollen wir so Eigenschaften wie Assoziativität und Kommutativität. Die History dieser Änderungen wird irrelevant, sondern nur noch die semantische, konkrete Änderung. Schon beinahe isoliert von seiner Umgebung.
Was wir in Zukunft also teilen werden, wird sich verändern. Es werden nicht mehr normaler Code sein, sondern Features oder Komponenten. Wie solche gespeichert und angewandt werden auf andere Projekte usw., weiss ich nicht.
LLMs sind die erste Hochsprache
Die Vision vieler Hochsprachen wie Pascal war es: Lasst uns einfach Englisch schreiben, was wir wollen, und der Computer macht es dann. Doch alle Ansätze funktionierten nicht. Es war immer einfach eine etwas lesbarere Version von einer puren Sprache. Viele wollten nicht die menschliche Sprache imitieren, sondern das menschliche Denken, und somit entstanden die objektorientierten Sprachen. Objekte sind da und tun etwas.
Aus meiner Sicht sind LLMs die Erfüllung dieser Vision. Jetzt können wir wirklich auf Englisch (oder sogar in einer anderen Sprache) ausdrücken, was wir wollen, und der Computer macht es. Es ist eine Revolution. Momentan sind noch immer die am effizientesten mit der KI, die es auch ohne KI machen könnten, doch ich bin mir nicht sicher, dass das so bleibt. Bzw. ich bin mir ziemlich sicher, dass es nicht so bleibt.
Ich erinnere mich noch gut an ein Gespräch mit einem alten Freund. Er war und ist sehr gebildet und intelligent (was nicht dasselbe ist). Er war jedoch eher sprachlich talentiert als mathematisch. Er erzählte mir von einem Aufsatz, den er als Auftrag schrieb, in dem er ad absurdum führte, dass ein Computer Menschen ersetzen könnte. Der hätte doch keine Kreativität, kein logisches Denken und keinen Antrieb. Dieser Aufsatz alterte schlecht. Ich sagte ihm schon damals, dass ich keinen fundamentalen Unterschied zw. Computer und Menschen finde und es kein Argument ist, es einfach absurd zu nennen. Es blieb bei diesem kurzen Austausch. Doch heute haben wir KIs mit Kreativität, Antrieb, und wenn wir die «Agents» zusammen mit einer Programmiersprache betrachten, dann besitzen sie jetzt auch Logik.
Wie bereiten wir uns vor?
Diese Entwicklung wird sich nicht aufhalten lassen. Als Direktbetroffener werde ich von Anfang an die Tools nutzen, am Ball bleiben und versuchen, Probleme zu lösen, die ich zuvor nicht konnte. Meinen Berufsstolz muss ich liegen lassen und ein Ja zu einer neuen Denkweise finden. Ich glaube, für uns persönlich ist es hilfreich, möglichst am Ball zu bleiben. Und das aktiv. Lasst uns Projekte umsetzen und nicht nur Blogartikel lesen. Als Firma dasselbe. Haltet nicht krampfhaft an euren alten Prozessen fest. Evaluiert andauernd. Als Politik: Open Data wird so wichtig wie noch nie. Mit KI kann man die schnell anzapfen und sich Berichte erstellen lassen. Die Entscheidungsfindung in Zukunft wird viel datengestützter sein.
Was haben wir gelernt? Und einige fundierte Vermutungen
Gödels Unvollkommenheitstheorie
Gödel ist einer der grossen Mathematiker des letzten Jahrhunderts. Unter anderem arbeitete er an den Grundlagen der Mathematik. Ihn interessierte die Frage, ob Mathematik «vollständig» ist. Um zu verstehen, was damit gemeint ist, brauche ich zuerst kurz den Begriff des Axioms.
Ein Axiom ist eine Annahme in einem mathematischen System, die nicht bewiesen wird. Mathematik kommt ohne solche Annahmen nicht aus. Ein bekanntes (wenn auch etwas vereinfachtes) Beispiel ist: $1+1=2$. Es wirkt so offensichtlich, dass man versucht ist zu sagen: «Dafür braucht es keinen Beweis.» Genau das ist die Intuition hinter Axiomen.
Als Axiom wählt man Aussagen, denen (im gewünschten Kontext) alle zustimmen können. Das bedeutet aber nicht: «Was mir offensichtlich erscheint, erkläre ich einfach zur Wahrheit.» Denn was für die eine Person offensichtlich ist, ist es für die andere vielleicht nicht. Darum schreiben Mathematiker ihre Axiome explizit auf und sagen sinngemäss: «Unter diesen Annahmen mache ich Mathematik.» Dann kann jede andere Person prüfen, ob die Schlussfolgerungen unter diesen Annahmen korrekt sind.
Ein Beispiel für solche Annahmen:
- A: 0 ist eine Zahl
- B: 1 ist eine Zahl
- C: Wenn $x$ eine Zahl ist, dann gilt: $x + 0 = x$
- D: Wenn $x$ eine Zahl ist, dann ist $x + 1$ auch eine Zahl
- E: $x+1 > x$
Mathematiker würden (zu Recht) sagen, dass das nicht formal genug ist. Für unsere Zwecke reicht es. Und man sieht: Solche Aussagen sind fast banaler Natur. Trotzdem lässt sich daraus bereits eine Aussage beweisen, die für Kinder eine echte Offenbarung ist: «Es gibt keine grösste Zahl.»
Beweis durch Widerspruch:
Angenommen, es gäbe eine grösste Zahl. Nennen wir sie $y$. Dann folgt aus D, dass $y+1$ ebenfalls eine Zahl ist. Nennen wir sie $z$. Aus E folgt $z>y$. Das widerspricht der Annahme, dass $y$ die grösste Zahl ist. Also gibt es keine grösste Zahl.
Das alles klingt nach spitzfindiger Haarspalterei, die Mathematiker betreiben, um Probleme zu lösen, die niemand hat. Und genau so dachte ein grosser Teil der Mathematik zu Beginn des 20. Jahrhunderts. Hier kommt Gödel ins Spiel. Die Beweisidee ist nicht «schwer», aber sie sprengt den Rahmen dieses Textes. (Wenn dich das interessiert: Sag’s, dann schreibe ich gern eine separate Erklärung.)
Die Kernaussage ist: Egal, wie viele Axiome du aufschreibst — es wird immer wahre Aussagen geben, die sich aus deinen Axiomen nicht beweisen lassen. Mathematik ist also unvollständig. Selbst mit «fünf Milliarden» Axiomen wirst du nie alle wahren mathematischen Aussagen beweisen können.
Was bedeutet das?
Die Hoffnung war einmal: Wenn wir nur genug forschen und schlau genug werden, können wir alles beweisen. Gödel zeigt: Nein — es gibt prinzipielle Grenzen.
Für mich folgt daraus: Egal, wie unser formales Denksystem aussieht, es bleiben immer Dinge, die für uns in diesem System unzugänglich sind. Praktisch heisst das: Man braucht eine Art, mit «nicht beweisbaren» Aussagen umzugehen. Aber man darf auch nicht ins andere Extrem kippen und behaupten, alles sei unbeweisbar. Schon die Behauptung, etwas sei unbeweisbar, kann (in einem anderen System) wieder beweisbar sein.
Wichtig: Das bedeutet nicht, dass man «nichts» beweisen kann. Mathematische Beweise liefern eine Art Gewissheit, die im Alltag selten vorkommt. Ich bin mir sicherer, dass es keine grösste Primzahl gibt, als dass ich einen Vater und eine Mutter habe. Letzteres ist zwar praktisch sicher, aber nicht logisch zwingend. Mathematische Gewissheit ist — wenn sie einmal sauber bewiesen ist — unerbittlich.
Komplexitätstheorie
Als Informatiker bin ich ständig mit Analysen über die Komplexität von Algorithmen konfrontiert. «Algorithmus» klingt gross, meint aber oft etwas Banales: einen Prozess, ein Verfahren. Zum Beispiel: der kürzeste Weg von A nach B. Man kann dann fragen, wie viel Zeit dieser Prozess im Durchschnitt, im besten oder im schlimmsten Fall braucht.
Komplexitätstheorie handelt genau von solchen Fragen: Was ist schneller? Was lässt sich optimieren? Bevor ich Informatik studierte, dachte ich naiv: «Wenn man nur sauber programmiert, wird es schnell.» Das stimmt manchmal — aber nicht immer. Manche Probleme bleiben langsam, selbst wenn man sie optimal implementiert.
Es gibt Aufgaben, die in der Praxis gut lösbar sind (z. B. sortieren, kürzeste Wege in grossen Netzen). Andere werden aber sehr schnell absurd schwierig. Ein Beispiel ist Routenplanung mit vielen Zwischenstopps, bei denen die Reihenfolge egal ist (klassisch: Varianten des Traveling-Salesman-Problems): Das skaliert exponentiell.
Und selbst bei Problemen, für die wir den «optimalen» Algorithmus kennen, kann das Ergebnis praktisch unbrauchbar sein. Schach ist ein schönes Beispiel: Perfektes Schach lässt sich «in Prinzip» berechnen, aber der dafür nötige Aufwand ist so gewaltig, dass das Universum eher aufhört zu existieren, als dass der Algorithmus fertig wird.
Was bedeutet das?
Nach Gödel kommt hier eine andere Art von Grenze: Es gibt Probleme, die lösbar sind. Es gibt eine eindeutige Antwort, und wir wissen sogar, wie man sie findet. Und trotzdem sind sie so langsam, dass sie praktisch als unlösbar gelten müssen.
Das ist weniger abstrakt als Gödel. Es gibt eine ganze Klasse solcher Probleme (Stichworte: NP‑vollständig, EXP‑Time). Wären diese effizient lösbar, sähe unsere Welt anders aus: neue Medikamente, optimierter Verkehr, und gleichzeitig wären viele Verschlüsselungsverfahren kaputt.
Und wichtig: Das ist nicht «nur» eine Grenze des Menschen. Wenn es keinen schnellen Algorithmus gibt, dann ist das auch eine Grenze für Maschinen — auch für KI.
Halteproblem
Spätestens hier ist endgültig klar: Informatik.
Das Halteproblem ist ein Thema, von dem viele nie hören — ausser sie studieren Informatik oder interessieren sich privat dafür. Und doch wäre die Welt völlig anders, wenn es lösbar wäre. Aber es ist es nicht.
Worum geht es?
Wir betrachten einen Algorithmus (ein Programm) und fragen: Hält er an — oder läuft er für immer? Die erste Intuition ist: «Schau den Code an. Wenn da eine Schleife ist, dann weiss man es.» Leider gibt es sehr viele Programme, bei denen man gerade nicht entscheiden kann, ob sie anhalten.
Was bedeutet das?
Vorher hatten wir Probleme, die «nur» praktisch unlösbar sind. Jetzt kommt etwas Seltsameres:
Ein Programm ist eindeutig. Entweder hält es an oder es hält nicht an. Dazwischen gibt es nichts. Und trotzdem gibt es keinen allgemeinen Prozess, der diese Frage für beliebige Programme zuverlässig beantworten kann.
Chaostheorie
Eine weitere Einschränkung unserer Möglichkeiten: Chaos.
«Chaos» meint hier nicht Alltagchaos, sondern einen mathematischen Begriff. Ein chaotisches System entwickelt sich je nach kleinsten Unterschieden im Ausgangszustand in völlig unterschiedliche Richtungen. Der Klassiker ist das Doppelpendel: Die Bewegung ist durch Naturgesetze klar bestimmt — und trotzdem ist es praktisch unmöglich, hinreichend weit in die Zukunft präzise vorherzusagen, wo es nach 100 Sekunden sein wird.
Viele relevante Systeme verhalten sich in diesem Sinn chaotisch: Wetter, langfristige Bahnprognosen, komplexe Stoßsysteme (z. B. viele Billardkugeln), und auch biologische bzw. medizinische Prozesse. Könnten wir diese Systeme zuverlässig «lösen», hätten wir Therapien für eine Vielzahl von Krankheiten.
Was bedeutet das?
Wieder eine Grenze — aber diesmal sehr praktisch.
Manche behaupten (oft nicht Wissenschaftler), die Welt bestehe «im Grunde» nur aus ein paar Naturgesetzen, und alles andere sei nur Ableitung. Daran ist einiges schief. Schon unsere aktuelle Physik ist kein vollständiges, widerspruchsfreies Gesamtbild. Und selbst wenn sie es wäre: Chaos bleibt.
Um von kleinen Systemen verlässlich auf grosse zu schliessen, müssten wir chaotische Effekte vollständig kontrollieren. Das gelingt in idealisierten Modellen vielleicht — in der realen Welt aber selten.
Das zwingt uns zu Abstraktionen, die nicht einfach «aus der Physik heraus» deduzierbar sind. Physik ersetzt nicht Chemie, Chemie ersetzt nicht Biologie, und bei Psychologie und Soziologie wird es erst recht schwierig.
Folge: Wir müssen oft mit statistischen, vereinfachenden und (im strengen Sinn) «falschen» Theorien arbeiten, weil die präzisere Wahrheit für uns unerreichbar bleibt. Das macht solche Modelle nicht wertlos — nur begrenzt.
Gradientenoptimierung
Das waren einige harte Grenzen. Sind wir damit grundsätzlich gelähmt?
Nicht ganz. Statt einer universellen Theorie können wir oft eine universelle Methode nutzen: Optimierung.
Im maschinellen Lernen wird das sehr konkret: Man baut ein System, das wenig «versteht». Es nimmt die Welt wahr, aber kennt die zugrunde liegenden Gesetze nicht. Dann gibt man ihm ein Feedback‑Signal: Wie gut war diese Aktion? Und das System versucht nicht zuerst, alles zu erklären, sondern iterativ besser zu werden.
Das Bild dazu: Ein Roboter steht am Berg und sieht nur einen Meter weit. Statt zu jammern, dass er den Gipfel nicht sieht und deshalb keinen perfekten Plan machen kann, macht er einfach den nächsten Schritt bergauf — und dann den nächsten. Irgendwann ist er oben. Vielleicht nicht auf dem Mount Everest, aber auf einem Berg, den er tatsächlich erreichen konnte.
Was bedeutet das?
Dieser Ansatz «belebt» die gelähmte Person: Man kann weitergehen, auch ohne allwissenden Plan.
Und das gilt nicht nur für Wissenschaft. Auch im Alltag ist der nächste sinnvolle Schritt oft besser als ein grandioser Masterplan. Statt «das Problem komplett lösen» kann man eine kleine Verbesserung machen. Statt «die Ehe retten» kann man heute ein ehrliches Kompliment machen. Statt «die Firma umkrempeln» kann man einem Kunden freundlich begegnen.
Es nimmt Druck raus: Man muss nicht alles verstehen, um anfangen zu handeln.
Der einzige «Plan» ist: Tu etwas Kleines und Gutes, von dem du begründet glaubst, dass es hilft.
Spieltheorie
Ah ja, Spieltheorie: das oft belächelte Stiefkind der Soziologie. Man wirft ihr vor, sie sei «unwissenschaftlich», weil sie mit Modellen arbeitet, die offensichtlich nicht die ganze Realität abbilden. Das stimmt — aber das gilt für fast alle Modelle. Und die Einsichten können trotzdem wertvoll sein.
Spieltheorie versucht, menschliche Interaktionen als Spiel zu formalisieren und dann zu analysieren, was unter bestimmten Annahmen rationales Verhalten wäre.
Ein klassisches Beispiel ist die «Tragödie der Allmende» (Tragedy of the Commons). Eine gemeinsame Wiese gehört dem Dorf. Alle Bauern dürfen ihre Kühe darauf weiden lassen. Das Problem: Jeder einzelne Bauer profitiert davon, noch eine Kuh zusätzlich zu schicken. Die Kosten — Überweidung, schlechtere Wiese — werden aber von allen gemeinsam getragen.
Selbst wenn niemand «böse» ist, entsteht so ein Mechanismus, der die gemeinsame Ressource zerstört. Und genau das ist die Pointe: Nicht moralische Kategorien sind zuerst entscheidend, sondern Anreize und Strukturen.
Spieltheorie liefert hier eine Denkweise: Welche Regeln würden Kooperation stabil machen? Wie verändern sich Ergebnisse, wenn man Gegenseitigkeit, Reputation oder Sanktionen einbaut? Und wenn ein System sogar unter der Annahme egoistischer Akteure stabil wäre, dann ist das ein starkes Indiz, dass es auch in der Realität robust ist.
Was bedeutet das?
Neben konkreten Ergebnissen aus Modellen bringt Spieltheorie etwas sehr Nützliches: Sie zwingt dazu, Egoismus als relevante Kraft ernst zu nehmen.
Egoismus wird oft moralisch abgewertet. Spieltheorie ist darin fast provokativ neutral: «Gut» ist erst einmal, was mir nützt. Das ist unbequem — aber hilfreich, wenn man die Welt verstehen will.
Das relativiert auch Moral und Ethik in einem bestimmten Sinn: Welche Wirkung hat «gutes Handeln», wenn es gegenüber anderen Strategien nicht bestehen kann? Handlungen müssen stark genug sein, um sich in der Welt zu behaupten.
Und ähnlich wie bei der Gradientenoptimierung schrumpft der Horizont: Nicht «die Welt retten» ist die Aufgabe, sondern in einer lokalen und zeitlich begrenzten Situation die bestmögliche Entscheidung zu treffen.
Evolution simulieren
Viele Menschen behaupten, dass Evolution unmöglich ist, weil nichts aus Zufall entstehen kann. Aber ist Zufall der einzige Faktor in der Evolution? Was, wenn andere Kräfte im Spiel sind, die die Vielfalt und Komplexität des Lebens lenken? Um diese Frage zu erforschen, habe ich einen Algorithmus entwickelt, der Evolution simuliert und überraschende Ergebnisse zeigt.
Der Code ist unter GitHub verfügbar.
Stell dir eine leere Welt vor. Ohne Sinn und Möglichkeiten. In dieser Welt taucht ein Roboter auf. Er kann nichts sehen. Sein visueller Input ist so leer wie das Universum, in dem er erschaffen wurde. Der Roboter hat keinen Willen. Er tut einfach etwas Zufälliges. Was er nicht weiss: Es gibt 50 andere Roboter, die gleichzeitig erschaffen wurden. Sie verhalten sich alle unterschiedlich. Einige wandern herum, einige stehen still, und einige drehen sich im Kreis. Dann tritt plötzlich eine änderung bei einem Roboter auf. Sein Input ändert sich. Er sieht etwas Rotes. Die anderen am selben Ort sehen es auch. Sie verhalten sich zufällig. Manche bewegen sich darauf zu, manche nicht. Was ist dieses rote Ding? Je näher ein Roboter kommt, desto klarer sieht er es, bis er es berühren kann. Von nichts bist du gekommen, und zu nichts wirst du zurückkehren. Der Roboter verschwindet. Jeder Roboter, der das rote Ding berührt, verschwindet. Er stirbt. Im Laufe der Zeit bleiben nur die Roboter, die sich entweder nicht bewegen oder vermeiden, das rote Ding zu berühren. Das geschieht automatisch, einfach durch die Gesetze dieses Universums. Wenn Roboter verschwinden, werden neue zufällig erschaffen und in die Welt geworfen, um die Bevölkerung vor dem Aussterben zu bewahren. Und es ward Abend und Morgen. Der erste Tag.
Am zweiten Tag stand ihnen ein neues Problem gegenüber. Es gab Gerüchte über ein grünes Ding. Die meisten Roboter verhielten sich gegenüber den grünen Dingen gleich, da die Evolution vorsichtige Individuen begünstigte. Aber einige Roboter verschwanden einfach, ohne die roten berührt zu haben. Ihre Lebensspanne war abgelaufen, und sie hatten das Geheimnis des Überlebens nicht herausgefunden. Nun ja, die meisten hatten es nicht. Einige hatten das zufällige Verhalten, sich den grünen Dingen zu nähern. Und als sie sie berührten, geschah etwas Magisches. Erstens verlängerten sie unwissentlich ihre Lebensspanne, und zweitens reproduzierten sie sich. Sie erstellten eine Kopie von sich selbst, sehr ähnlich, aber leicht anders, mit einer zufälligen Variation im Verhalten. Das ändert alles. Anstatt nicht zu sterben, wurde Reproduktion das neue Ziel des Spiels. Bald vermieden alle Roboter das rote Zeug und suchten das grüne Zeug.
Jetzt kommt die nächste Etappe. Vorher war Vorsicht der Schlüssel. Bewege dich langsam, um das Risiko zu reduzieren, versehentlich die roten Minen zu berühren. Aber nach einiger Zeit wurden einige Roboter zufällig schneller, und sie waren immer die ersten bei den grünen magischen Früchten. Die vorsichtigen Roboter verhungerten, weil die schnelleren zuerst da waren. Geschwindigkeit ist jetzt der Schlüssel. Aber sie müssen jetzt mehr Risiken eingehen. Viele Roboter sterben jetzt wegen der Minen, aber solange sie sich schneller vermehren, dominieren sie diese Welt.
Die letzte Etappe. Jetzt haben die Roboter ohne menschliches Eingreifen nützliches Verhalten entwickelt, einfach weil sie dieser sehr spezifischen Umgebung ausgesetzt waren. Jetzt bleibt nur noch eine letzte Optimierung. Sie müssen langsam, aber sicher die Minen vermeiden und ihre Basisgeschwindigkeit maximieren. Nach dieser Entwicklung wird ein Gleichgewicht erreicht, und aus reiner Zufälligkeit ohne Programmierung ist intelligentes Verhalten in Bezug auf diese Umgebung entstanden.
Nicht-optimierte Roboter
Optimierte Roboter
Sichtfeld des Roboters visualisiert
PyTorch ist langsam und schnell unter Windows
Für ein Projekt bei der Arbeit musste ich ein neuronales Netzwerk trainieren. Ich habe einen Windows-Laptop mit einer guten GPU. Wenn ich unter Windows entwickle, ist mein erster Ansatz, im WSL (Windows Subsystem für Linux) zu arbeiten. Und es funktionierte auch. Ich bemerkte jedoch, dass meine GPU-Nutzung nicht optimal war. Deshalb habe ich es auch unter nativem Windows ausgeführt.
| Metric | Nativ Windows | WSL |
|---|---|---|
| Training | 2.2 it/s | 1.3 it/s |
| Eval | ~5 it/s | 1.5it/s |
| Thread-Erstellung | 46s | ~5s |
| Thread-Erstellung | 54s | ~5s |
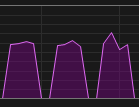
| GPU-Nutzung Training | 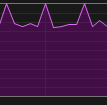 |
 |
| GPU-Nutzung Val | 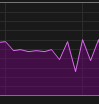 |
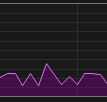 |
Ich habe dieses Wissen genutzt, indem ich jetzt unter nativem Windows laufe, aber mit persistenten Workers, sodass die Threads nicht in jeder Epoche neu erstellt werden müssen.
Natürlich ist dies nur ein Beispiel. Mit einer anderen PyTorch-Version könnte sich das ändern. Vielleicht verhält es sich mit einer anderen GPU anders.
Die langsame Thread-Erstellung ist ein bekanntes Problem, wenn man Foren betrachtet, aber die signifikante Leistungssteigerung bei Verwendung von nativem Windows war unerwartet.
Podman ist genauso schnell wie natives WSL.
Anaconda ist in diesem Setup auch nicht schneller als normales Python.
Neuronale Netzwerke komprimieren
Als ich mich um eine PhD-Position beworben habe, wollte ich dem Professor einen Grund geben, mich anzuheuern – also habe ich eine meiner Ideen umgesetzt. Ich vermutete, dass die Gewichte neuronaler Netzwerke zu dicht sind. Es gibt viel Redundanz. Die konventionelle Methode zur Reduktion der Komplexität besteht darin, einen Engpass in die Architektur des neuronalen Netzwerks einzuführen. Das ist jedoch eine ressourcenintensive Lösung. Anstatt die Anzahl der Gewichte zu reduzieren, erhöhen wir sie. Eine weitere Möglichkeit, die Komplexität eines Modells zu reduzieren, besteht darin, die Präzision der Gewichte zu senken, z.B. von 32-Bit auf 8-Bit. Das ist ein legitimer Ansatz, aber wenig inspirierend. Und es ist schwer zu glauben, dass das der einzige und richtige Weg für alle Situationen ist.
Meine Hypothese war, die Gewichtsmatrix mit einem gängigen Algorithmus wie JPEG zu komprimieren. Ich nahm MNIST und trainierte ein kleines CNN:
hidden_layer_size = 512
linear1 = torch.nn.Linear(784, hidden_layer_size, bias=True)
linear2 = torch.nn.Linear(hidden_layer_size, 10, bias=True)
relu = torch.nn.ReLU()
model = torch.nn.Sequential(linear1, relu, linear2)
Die Grösse von 512 für die Hidden Layers war die erste Zweierpotenz, die gute Ergebnisse lieferte.
Die 784 stammt aus der Eingabegrösse, die 28 × 28 beträgt.
Die Hidden Layer ist somit eine Liste von 512 verschiedenen 28 × 28 Matrizen.
Ich nahm jede Matrix und komprimierte sie mit JPEG auf eine Qualität von nur 20%, verlor also viele Informationen, wie hier zu sehen:
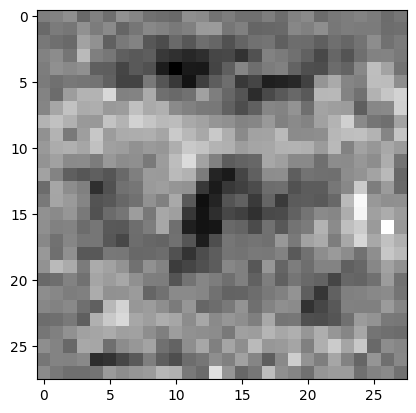 Zufällige unkomprimierte Gewichtsschicht
Zufällige unkomprimierte Gewichtsschicht
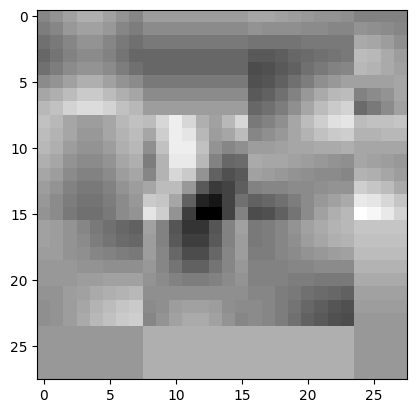 Dieselbe Gewichtsschicht, aber mit JPEG komprimiert
Dieselbe Gewichtsschicht, aber mit JPEG komprimiert
Die Test-Accuracy sank nur von 97% auf 96%, was angesichts der geringeren Auflösung im latenten Raum bemerkenswert ist.
Die Gewichte in einem CNN sind sehr redundant. Mit einem naiven Algorithmus wie JPEG können wir die Dimensionalität deutlich reduzieren. Für die Vorwärtspropagation im Netzwerk brauche ich jedoch die Matrixversion von JPEG, die keinen Speicher spart. Die komprimierten Gewichte könnten verwendet werden, um sie über ein Netzwerk mit geringer Bandbreite wie das Internet zu übertragen. Wir können jedoch einige fundierte Annahmen treffen:
- Die Wahl einer anderen Basis für die Gewichte, etwa die Fourier-Basis, anstatt ein unabhängiges Gewicht an jeder Position, könnte die Erstellung grosser Netzwerke mit einer begrenzten Anzahl von Gewichten ermöglichen.
- Diese Methode könnte auch in tiefen neuronalen Netzwerken funktionieren.
- Die Entwicklung einer differenzierbaren Methode, die mit wenigen Parametern erhebliche Komplexität erzeugt, könnte die Rechenfähigkeiten bestehender Hardware verbessern.
Ein gescheitertes Experiment: Gewichte innerhalb eines neuronalen Netzwerks komprimieren
In neuronalen Netzwerken scheint es viele Gewichte zu geben, um auszudrücken, was wir wollen. Also dachte ich daran, die grundlegendste Operation – nämlich die Matrixmultiplikation – in einer komprimierten Version zu implementieren. Statt einfach zwei Matrizen zu multiplizieren, komprimieren wir die Gewichtsmatrix und multiplizieren diese. Ich benutzte Wavelet-Zerlegung mit einem Schwellenwert. Mein Ansatz war erfolgreich darin, die Gewichtsmatrix während des Trainings zu 75% auf Null zu setzen.
Ich benutzte so etwas:
coeffs = ptwt.wavedec(w_flat, "haar", mode="zero")
coeffs_thresh = tuple(
torch.where(torch.abs(c) < threshold, torch.zeros_like(c), c)
for c in coeffs
)
w_compressed = ptwt.waverec(coeffs_thresh, "haar")
Während das Netzwerk folgendermassen aussah:
class NetFC(nn.Module):
def __init__(self):
super(NetFC2, self).__init__()
self.fc1 = CompressedLinear(784, 128, zero_fraction=0.75)
self.fc2 = CompressedLinear(128, 64, zero_fraction=0.75)
self.fc3 = CompressedLinear(64, 10, zero_fraction=0.75)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
return x
Dieses Netzwerk hat rund 100k Parameter, von denen 75k Null sein werden.
Aber der Leistungsabfall war zu hoch. Ich konnte meinen MNIST-Loss nur auf 0,55 bringen, während ein Netzwerk ohne Kompression, aber mit weniger (25k) Parametern problemlos 0,15 erreichte.
Es war also ein interessanter Ansatz, aber nicht erfolgreich.
